deep_learning_assignment
Assignment 1: Image Classification
Dataset: Food-101 It contains images of food, organized by type of food. It was used in the Paper “Food-101 – Mining Discriminative Components with Random Forests” by Lukas Bossard, Matthieu Guillaumin and Luc Van Gool. It’s a good (large dataset) for testing computer vision techniques. This document summarizes the workflow implemented in source/assignment_1/image/image.ipynb.
Exploratory Data Analysis (EDA)
The notebook first validates dataset structure after downloading from Kaggle, then performs quick visual inspection and descriptive analysis:
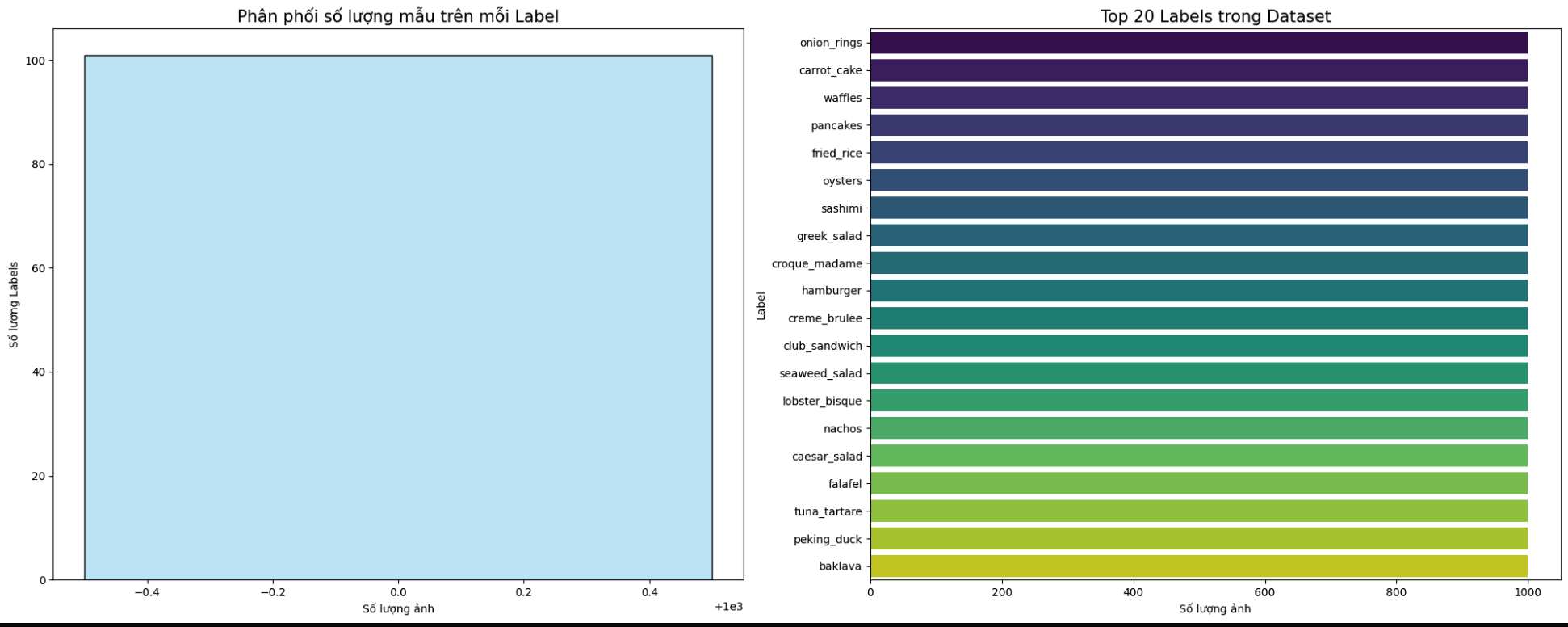
- Random sample visualization by class (
visualize_samples) - Label-wise sample counting (
analyze_dataset) - Distribution plots with histogram and bar charts (
visualize_dataset_stats)

Data Preparation
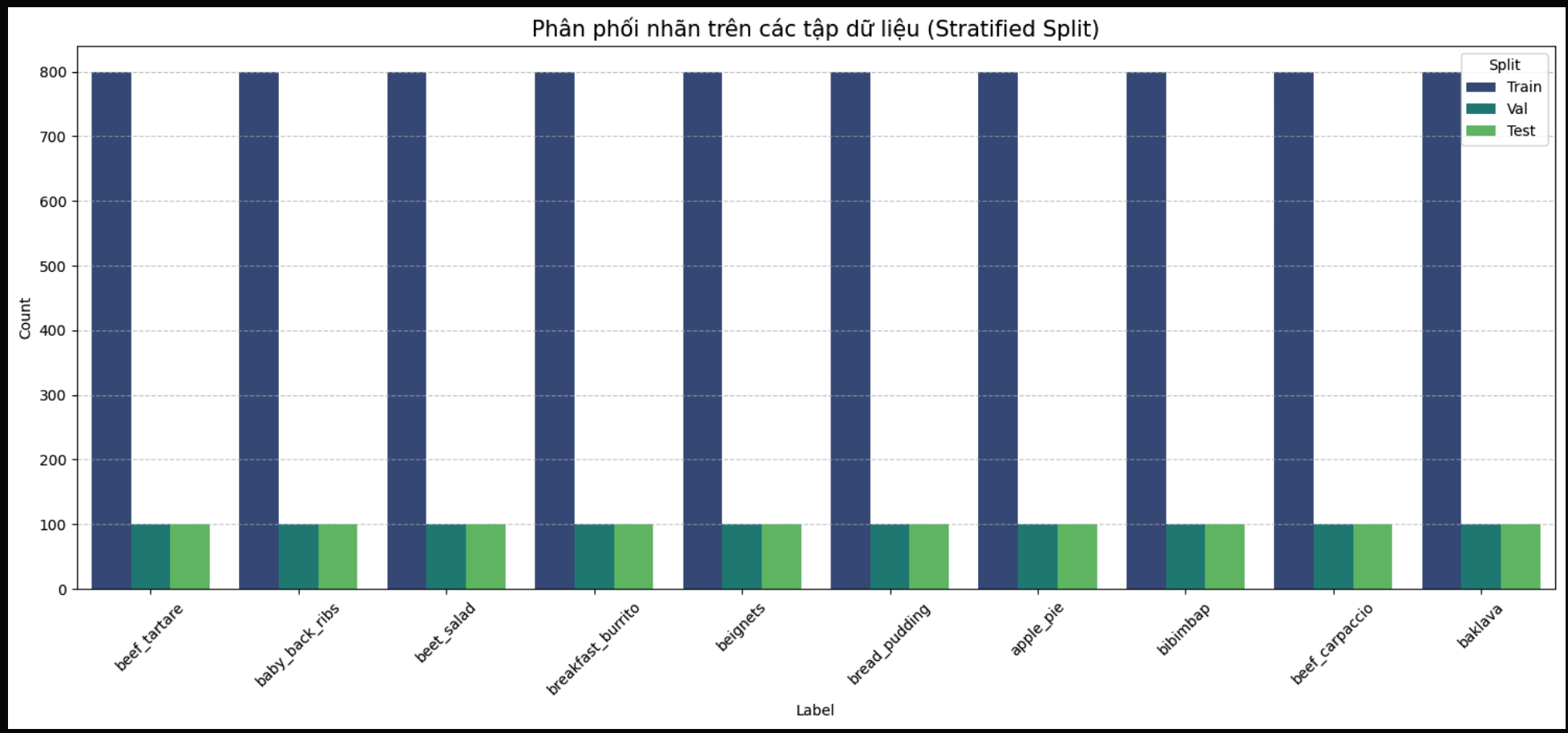
For faster experimentation, the workflow trains on 10 selected labels.
- Build
ImageFolderfromimages/ - Filter indices for 10 labels
- Stratified split: 80% train, 10% validation, 10% test
- Apply transforms:
Resize(224, 224)ToTensor()- ImageNet normalization
- Create DataLoaders for train/val/test
This keeps class balance across splits and provides a consistent pipeline for both models.
Model Summary
Two transfer-learning models are trained and compared:
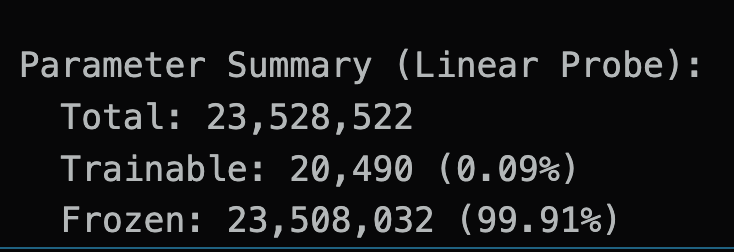
1. ResNet Branch
- Pretrained ResNet backbone
- Classification head replaced by
Linear(..., 10) - Backbone frozen for linear probing
2. ViT Branch
- Pretrained Vision Transformer from
timm - Classification head replaced by
Linear(..., 10) - Backbone frozen for linear probing
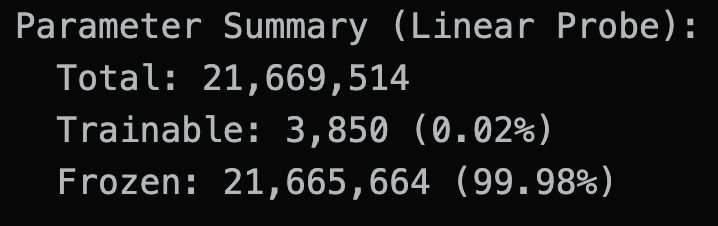 Both branches print trainable vs frozen parameter counts before training.
Both branches print trainable vs frozen parameter counts before training.
Training Settings
Training is managed by a shared Trainer class.
- Loss: Cross-Entropy Loss
- Optimizer: Adam (
lr=1e-4) - Metrics tracked each epoch:
- train loss / train accuracy
- validation loss / validation accuracy
- Checkpoint rule: keep best weights based on validation loss
- Safety stop: if validation loss increases versus previous epoch, trigger early emergency stop
The notebook trains both branches sequentially and saves best checkpoints.
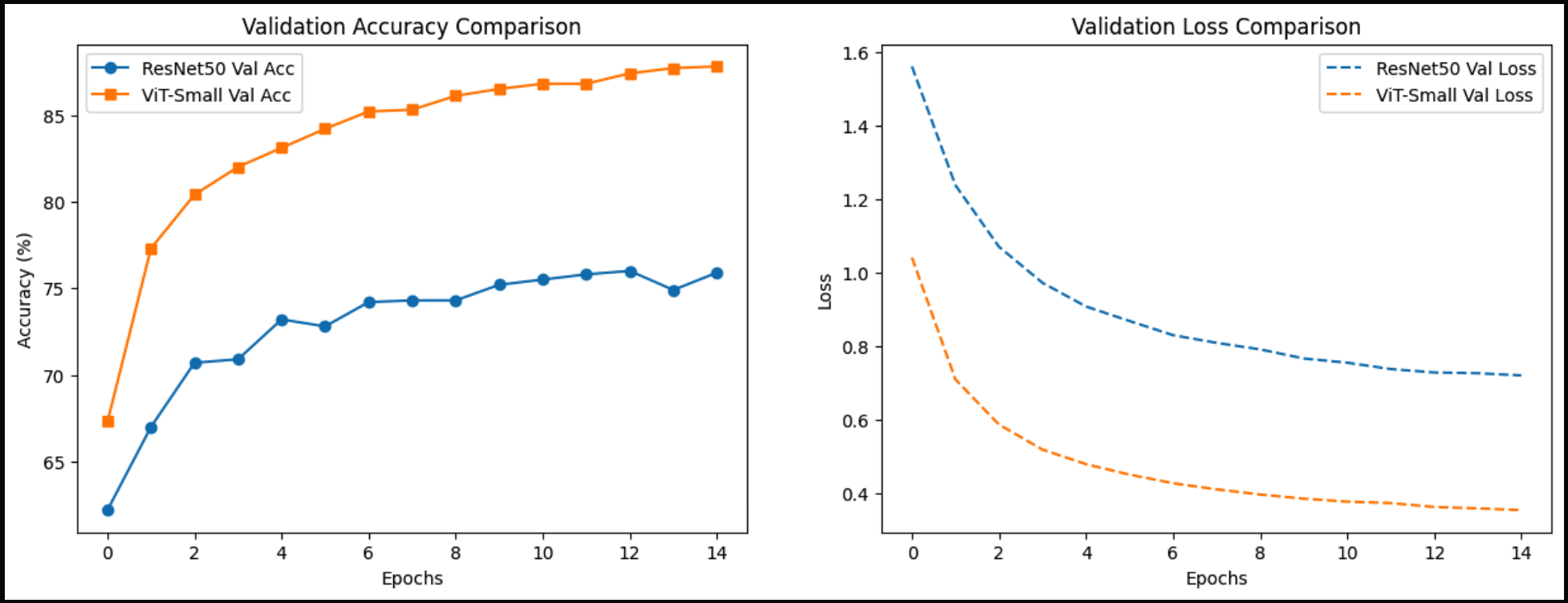
Results & Comparison
The notebook compares both models using:
- Validation curves (accuracy and loss)
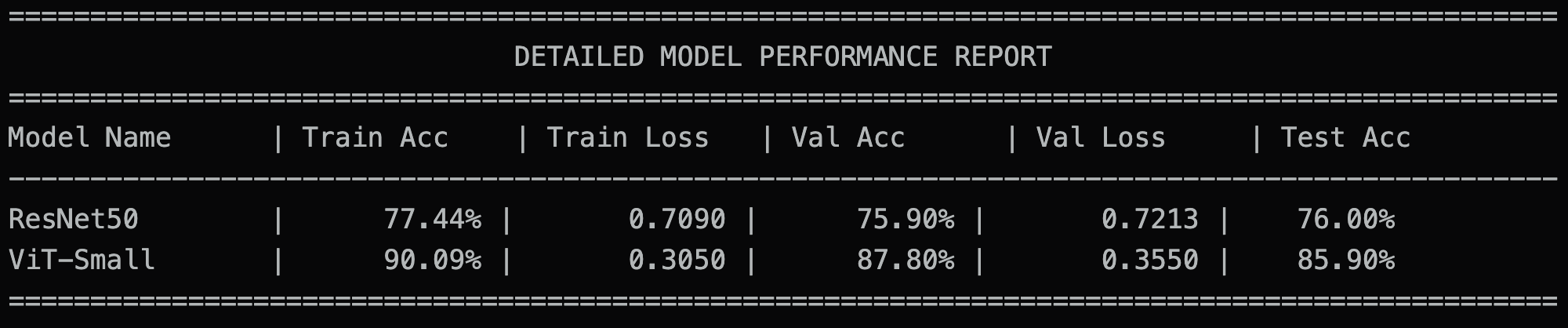
- Final test accuracy
- Consolidated comparison table (
final_comparison,final_comparison_v2)
This provides a direct baseline comparison between CNN-based and Transformer-based image classifiers on the same 10-label subset.
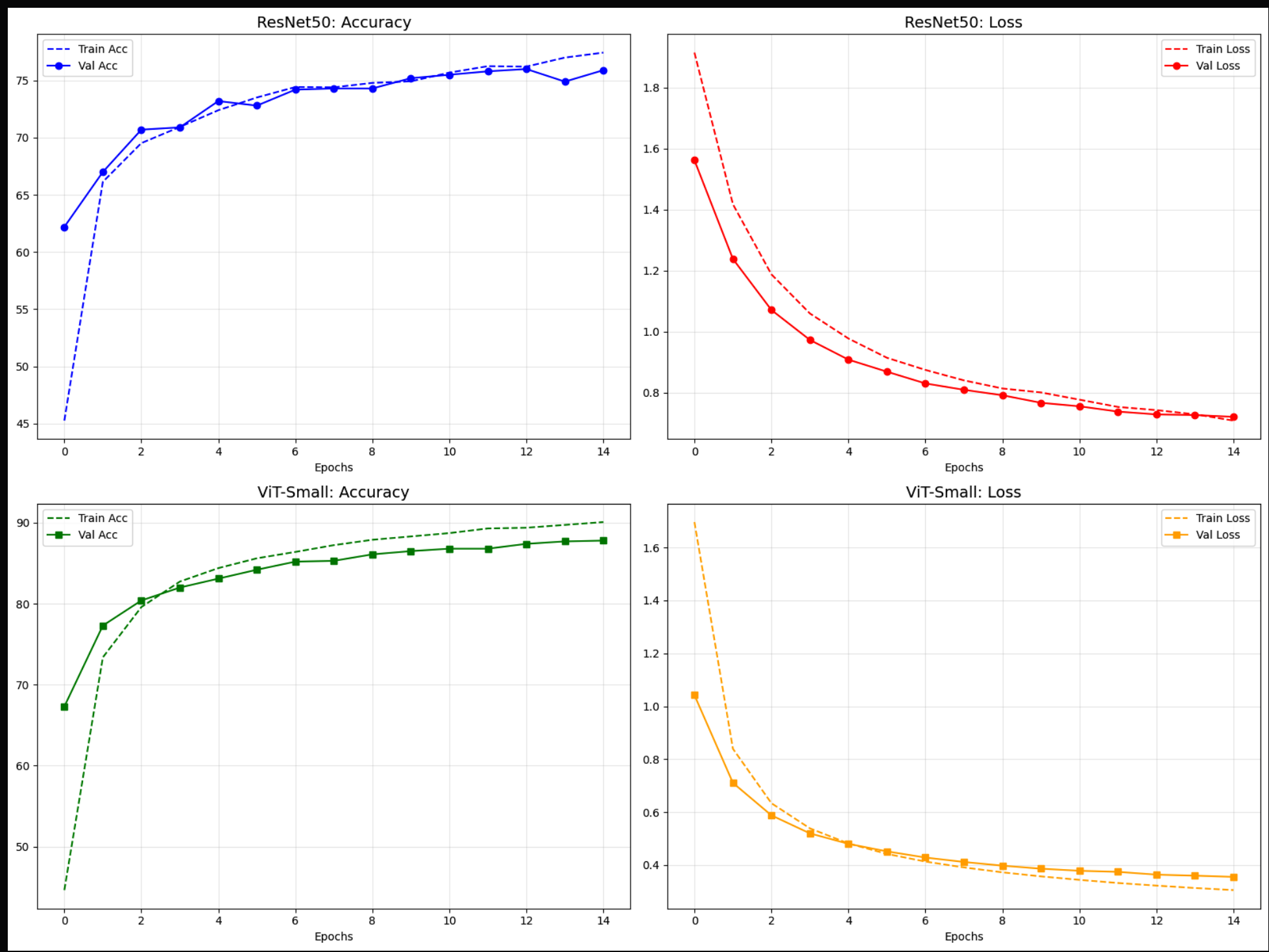
Analysis & Discussion
This experiment highlights an important practical observation: the ViT branch converges faster and achieves stronger performance than the ResNet branch within the same training budget, even though the configured ViT variant in this workflow uses fewer trainable parameters in the linear-probe setup.
1. Why ViT converges faster here
- With transfer learning, ViT starts from strong pretrained representations and can adapt quickly to the selected 10-class subset.
- In this setup, only the classifier head (and later a small part of the backbone) is optimized, so optimization remains lightweight.
- Validation curves show that ViT reaches stable performance in fewer epochs, while ResNet typically improves more gradually.
2. Why ViT can outperform ResNet with fewer trainable parameters
- Parameter count alone does not determine final accuracy.
- Architecture and representation quality matter: ViT benefits from global attention and robust pretrained features.
- For this subset-based food classification task, those pretrained features transfer effectively, giving better accuracy-efficiency trade-offs.
3. Why sampling is necessary for this assignment
- Food-101 is relatively large for iterative classroom experimentation.
- Running full-scale training for every model/hyperparameter change would be slow and costly.
- Sampling to a controlled subset (10 labels) enables:
- Faster prototyping and debugging.
- Fair side-by-side model comparison under equal data budget.
- More frequent iteration cycles within limited compute time.
In short, the sampling strategy is not only a speed optimization; it is a practical experimental design choice that makes model comparison feasible and reproducible.