SEML31
Assignment 2: Text Data
Group TN01 - Team SEML31
Colab Notebook: Assignment 2
1. Overview
- Dataset: Sentiment140 dataset containing 1.6 million tweets.
- Objective: Predict the sentiment (binary classification) of a user based on tweet text.
- Labels: Although the original dataset specification lists three labels (positive, neutral, negative), the actual data contains only two: Negative (0) and Positive (4).
2. Exploratory Data Analysis (EDA)
- Balance: The dataset is perfectly balanced with 800k samples for each class.
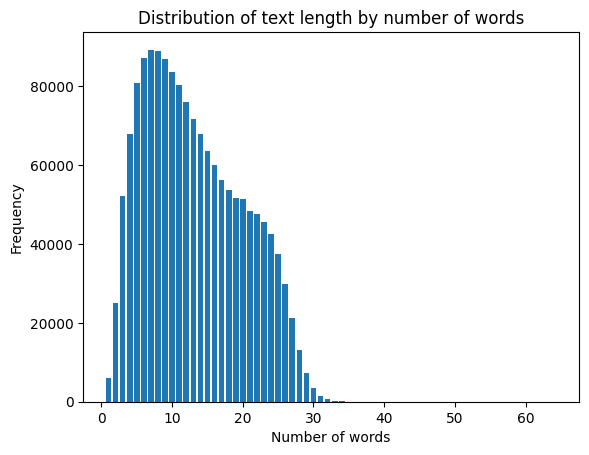
- Word Count Distribution: The text length by word count follows a right-skewed distribution (Mode < Median < Mean), typical for natural language.
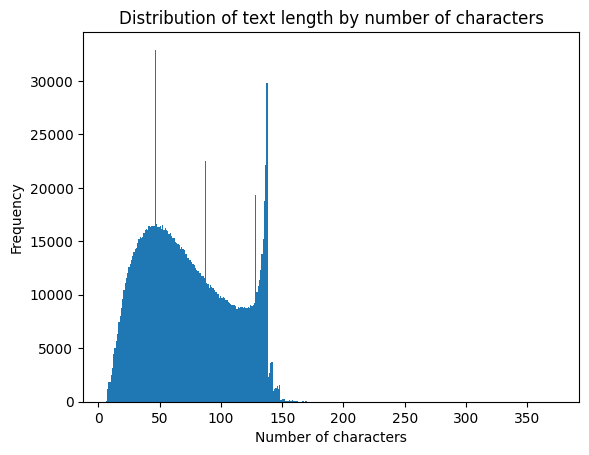
- Character Count Distribution: The character count distribution is appeared to be bimodal. It features a broad peak around 40-50 characters and a sharp, narrow spike at 140 characters. This spike directly reflects the historic Twitter character limit, indicating many users maximized their message length.
- Word Frequency: The most frequent words are common English stop words (i, to, the, a), which carry little sentiment value on their own.
3. Preprocessing
We applied the following pipeline to clean the raw text:
- Lowercase: Normalize all text to lowercase.
- Noise Removal: Remove URLs, usernames (e.g., @user), and special characters/punctuation.
- Stop Word Removal: Applied only for TF-IDF models to reduce noise.
- Lemmatization: Convert words to their base forms (e.g., learning $\to$ learn) to consolidate vocabulary.
4. Feature Extraction
Due to the dataset size, we utilized a stratified subset of 100,000 samples for training and testing. We employed two distinct embedding strategies:
- TF-IDF (Bag of Words): Focuses on word frequency. We removed stop words to prioritize meaningful content.
- Variants: Max features (2500 vs 5000) and Dimensionality Reduction (SVD 300).
- BERT (Contextual Embeddings): A pre-trained transformer model. We kept stop words because BERT relies on sentence structure and context to generate accurate embeddings (768 dimensions).
Feature Configurations:
| ID | Feature Type | Dimensions | Preprocessing |
|---|---|---|---|
| 1 | TF-IDF | 2500 | No stop words |
| 2 | TF-IDF | 5000 | No stop words |
| 3 | TF-IDF + SVD | 2500 -> 300 | No stop words |
| 4 | TF-IDF + SVD | 5000 -> 300 | No stop words |
| 5 | BERT | 768 | Keep stop words |
5. Modeling Strategy
We evaluated 30 models across three categories using Accuracy, Recall, Precision, and F1-score.
A. Linear Models
- Algorithms: Logistic Regression, LinearSVC.
- Hyperparameters: Regularization parameter $C \in {0.5, 1, 2}$.
- Input: TF-IDF (2500/5000) and BERT. SVD was skipped for linear models as they handle high-dimensional sparse data well.
B. Tree-based Models
- Algorithms: RandomForest, XGBoost.
- Hyperparameters: $n_estimators \in {50, 100}$.
- Input: TF-IDF (with SVD 300) and BERT. SVD is crucial here to reduce sparsity for tree splits.
C. Neural Networks (MLP)
- Architecture:
- BERT: Hidden layers [256, 32].
- TF-IDF (SVD): Hidden layers [128, 32].
- Training: Adam optimizer, Early Stopping (patience=5), Dropout.
6. Results & Discussion
Logistic Regression
| classifier | model_config | preprocessing | accuracy | precision | recall | f1 |
|---|---|---|---|---|---|---|
| Logistic Regression | 0.5 | tfidf_2500 | 0.7721 | 0.7911 | 0.7635 | 0.7771 |
| Logistic Regression | 0.5 | tfidf_5000 | 0.7760 | 0.7941 | 0.7678 | 0.7807 |
| Logistic Regression | 0.5 | bert | 0.7834 | 0.7866 | 0.7831 | 0.7848 |
| Logistic Regression | 1.0 | tfidf_2500 | 0.7728 | 0.7925 | 0.7639 | 0.7779 |
| Logistic Regression | 1.0 | tfidf_5000 | 0.7778 | 0.7957 | 0.7695 | 0.7824 |
| Logistic Regression | 1.0 | bert | 0.7831 | 0.7865 | 0.7826 | 0.7846 |
| Logistic Regression | 2.0 | tfidf_2500 | 0.7720 | 0.7929 | 0.7624 | 0.7773 |
| Logistic Regression | 2.0 | tfidf_5000 | 0.7782 | 0.7962 | 0.7698 | 0.7828 |
| Logistic Regression | 2.0 | bert | 0.7831 | 0.7859 | 0.7829 | 0.7844 |
Linear SVC
| classifier | model_config | preprocessing | accuracy | precision | recall | f1 |
|---|---|---|---|---|---|---|
| Linear SVC | 0.5 | tfidf_2500 | 0.7702 | 0.7952 | 0.7587 | 0.7765 |
| Linear SVC | 0.5 | tfidf_5000 | 0.7750 | 0.7962 | 0.7652 | 0.7804 |
| Linear SVC | 0.5 | bert | 0.7839 | 0.7883 | 0.7828 | 0.7856 |
| Linear SVC | 1.0 | tfidf_2500 | 0.7692 | 0.7943 | 0.7577 | 0.7755 |
| Linear SVC | 1.0 | tfidf_5000 | 0.7724 | 0.7931 | 0.7630 | 0.7778 |
| Linear SVC | 1.0 | bert | 0.7839 | 0.7883 | 0.7828 | 0.7856 |
| Linear SVC | 2.0 | tfidf_2500 | 0.7690 | 0.7941 | 0.7576 | 0.7754 |
| Linear SVC | 2.0 | tfidf_5000 | 0.7710 | 0.7920 | 0.7615 | 0.7764 |
| Linear SVC | 2.0 | bert | 0.7839 | 0.7884 | 0.7828 | 0.7856 |
Random Forest
| classifier | model_config | preprocessing | accuracy | precision | recall | f1 |
|---|---|---|---|---|---|---|
| Random Forest | 50.0 | svd_2500 | 0.7056 | 0.6891 | 0.7145 | 0.7016 |
| Random Forest | 50.0 | svd_5000 | 0.7087 | 0.6867 | 0.7202 | 0.7030 |
| Random Forest | 100.0 | svd_2500 | 0.7160 | 0.7071 | 0.7216 | 0.7143 |
| Random Forest | 100.0 | svd_5000 | 0.7191 | 0.7026 | 0.7284 | 0.7152 |
XGBoost
| classifier | model_config | preprocessing | accuracy | precision | recall | f1 |
|---|---|---|---|---|---|---|
| XGBoost | 50.0 | svd_2500 | 0.7242 | 0.7430 | 0.7177 | 0.7301 |
| XGBoost | 50.0 | svd_5000 | 0.7282 | 0.7383 | 0.7253 | 0.7318 |
| XGBoost | 50.0 | bert | 0.7563 | 0.7579 | 0.7570 | 0.7575 |
| XGBoost | 100.0 | svd_2500 | 0.7260 | 0.7435 | 0.7200 | 0.7315 |
| XGBoost | 100.0 | svd_5000 | 0.7314 | 0.7432 | 0.7277 | 0.7354 |
| XGBoost | 100.0 | bert | 0.7621 | 0.7621 | 0.7636 | 0.7629 |
MLP
| classifier | model_config | preprocessing | accuracy | precision | recall | f1 |
|---|---|---|---|---|---|---|
| MLP | Dropout + Scheduler + Early Stopping | bert | 0.7909 | 0.7738 | 0.8026 | 0.7879 |
| MLP | Dropout + Scheduler + Early Stopping | svd | 0.7437 | 0.7524 | 0.7411 | 0.7467 |
Best Models
| classifier | model_config | preprocessing | accuracy | precision | recall | f1 |
|---|---|---|---|---|---|---|
| Logistic Regression | 0.5 | bert | 0.7834 | 0.7866 | 0.7831 | 0.7848 |
| Linear SVC | 2.0 | bert | 0.7839 | 0.7884 | 0.7828 | 0.7856 |
| Random Forest | 100.0 | svd_5000 | 0.7191 | 0.7026 | 0.7284 | 0.7152 |
| XGBoost | 100.0 | bert | 0.7621 | 0.7621 | 0.7636 | 0.7629 |
| MLP | Dropout + Scheduler + Early Stopping | bert | 0.7909 | 0.7738 | 0.8026 | 0.7879 |
7. Key Insights
-
BERT Supremacy: BERT embeddings consistently outperformed TF-IDF across almost all classifiers. This confirms that capturing context and semantic meaning (bidirectional) is superior to simple keyword frequency (TF-IDF) for sentiment analysis, especially in short, informal texts like tweets.
- Effectiveness of Linear Models:
Surprisingly, Linear Models (Logistic Regression/SVC) performed very competitively with TF-IDF features.
- Insight: High-dimensional sparse text data is often linearly separable.
- Regularization: Lower $C$ values (0.5) yielded slightly better accuracy (~0.5% gain), suggesting that stronger regularization helps generalize better on noisy social media data.
-
Tree-based Model Limitations: Random Forest and XGBoost showed only marginal improvements when increasing estimators from 50 to 100 (~1% gain). Given the high computational cost, the return on investment for scaling up tree models on this specific task is low compared to using a better embedding (BERT).
- MLP Performance: The MLP trained on BERT embeddings achieved the highest overall metrics. The combination of dense, rich semantic vectors from BERT and the non-linear learning capability of the MLP allowed the model to capture subtle sentiment nuances that linear models missed.